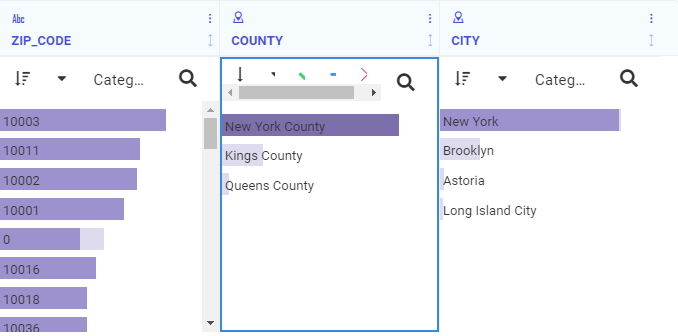
Chaining Filter Control Selections
When a content item or page includes multiple filters, chaining ensures that those filters always return valid values to your content. When you select a value from one of the filter controls, the other controls can be filter and updated based on the value that you select, if chaining is applied. For example if you have a filter for Sale Quarter chained to a filter for Sale Month, then when you select Q1 from the Sale Quarter filter, the Sale Month filter updates to show only the months of January, February, and March, and automatically excludes any month values that were not in Q1.
 ).
).
 )
)