Introducing Joins
Your data may be arranged and structured in different ways depending on the size and amount of detail that it provides. Smaller data sources may be saved in a single spreadsheet or flat file, such as a CSV file, making them easy to access and distribute. Larger data sources, however, may contain too many records or fields to efficiently store in a single file.
These large data sources may include numerous fields with additional information about more general fields, allowing you to analyze your data based on additional characteristics. For example, you may have data about sales that includes an identifier for the product that was sold or the location where the sale was made. You can then use a separate table to store information about the product or location so that your primary sales table does not include too much extraneous information, saving space and making it easier to extract the information that you need from your data source. These separate tables may be stored in different databases on the same server, or in completely different data sources. Any files with matching data can be joined. For example, you may have data in a spreadsheet that you wish to join to data from tables in a relational database. However, there may be some impact to performance in retrieving data values from different sources.
One common practice when administering and joining your data is to organize your data in fact tables and dimension tables. Typically, quantitative measure fields are stored in fact tables, and qualitative dimension fields are stored in dimension tables. The sales table mentioned previously, which includes measure fields that can be aggregated based on categorical dimension field values, is an example of a fact table. Fact tables include separate records for each datum, event, or observation that is tracked and written to your data source. These records could represent sales or other transactions, survey responses, shipments, scientific measurements, and more. Quantitative metrics for these records are recorded in measure fields. Each record in the fact table is identified by a key value. The key value, stored in its own field, helps identify and distinguish each record from the other records in the table. Fact tables may also include ID fields that represent different basic dimension values, such as the item, location, and date associated with each record.
These ID fields are associated with more detailed information in dimension tables. For example, you may have separate dimension tables with information about the item that was sold or shipped, the location of a store or customer address, and additional time and date information.
You can match the measure values of individual records from your fact table to information about different dimension values in your dimension tables using joins. Joins are made by matching dimension values in one table to the same values in another table. In many cases, this is done by matching ID values in one table to the same ID values in a key field in another table. For example, the following image shows how a data value for an individual sale is matched to information about the store where that sale was made, using a join.
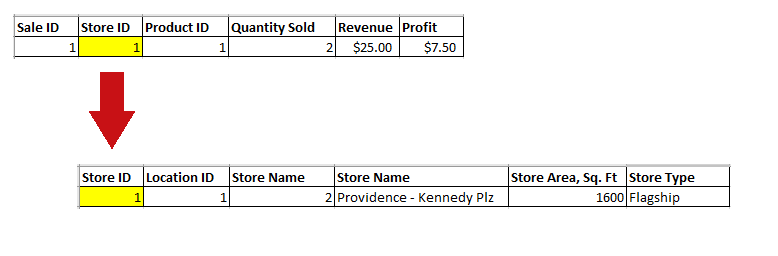
Based on the join created in the previous image, we now know that a sale of two items, for a revenue of $25.00, was made at the Providence - Kennedy Plaza store, even though this information is split between two separate tables. They are matched based on the store ID value. You could use another unique value, such as the store name, to create joins, as long as the same field is available in both tables, but ID numbers are more reliable since names are prone to duplication (for example, Portland as a city in both Maine and Oregon) and potential misspelling.
One table can be joined to multiple other tables. For example, if a fact table contains multiple ID fields, it can be joined to multiple dimension tables that use those ID fields as key fields. The ID field in the fact table and the key field in the dimension table must contain the same values for the join to work properly. If some of the values do not match, depending on the join type, they may be excluded from the join or return missing values. Dimension tables can also contain other ID fields that can be used in joins to connect to even more information in other dimension tables. This allows you to create a multi-level hierarchy of tables in data sources using joins. These are called clusters, and can be structured in many different ways depending on how the tables in your data source are joined, such as in a star schema or snowflake schema. These schemas are common structures used in data warehouses and data marts, which are subsets of a data warehouse focused on specific departments or other groupings. The structure of your cluster synonym will be determined by the fields that are shared between tables in your data warehouse or data mart. You can then, when configuring your metadata, create a Business View to show the fields in a more logical manner for when the synonym is used to create content. The Business View does not need to match the structure used in the data warehouse or in the cluster synonym, and can effectively present the fields in a way that is easy to navigate and defines relationships between fields. The following image shows the join structure of the WebFOCUS Retail Demo sample data that you can load to your environment from the WebFOCUS Reporting Server Console.
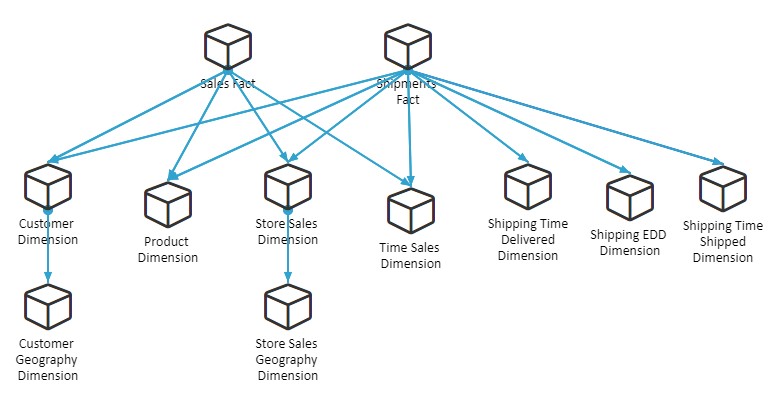
Notice that this cluster contains two fact tables, and that each of the dimension tables is joined to multiple fact or dimension tables. Even the Geography table was joined twice — once to the Customer dimension table, and once to the Store Sales dimension table. Each of the joins provides geographic information for a separate set of location values.
Once you have uploaded or connected to data sources to create your metadata, you can join the tables or resulting synonyms together in one of two ways:
- As part of a cluster synonym, in the WebFOCUS Reporting Server Console. Once saved, you can reuse the cluster synonym, with all joined data included, as the data source for multiple content items. You can make the cluster synonym available to other users so that the data used in these content items remains consistent without having to recreate the joins. If you have multiple tables that you always want to be available together when creating content, a cluster synonym is a good way to provide them.
When you select the tables that you want to use in the cluster, they are joined automatically, if possible, based on whether the fields have a primary key-foreign key relationship or matching field names and formats. By default, the joins are displayed in a modeling view, which displays multiple branching join paths. - As part of a single content item, such as a chart, a report, or a workbook. You can create joins in the following content creation tools:
Since you create these joins ad hoc for use in your content, they are saved as part of the individual procedure. They are not saved as part of the data source like joins in a cluster synonym are. Since joins made in your content are independent of the data source, this is a good way to perform quick data exploration.
- WebFOCUS Designer. Provides a straight-forward set of options to perform data exploration by creating charts and workbooks.
- InfoAssist. Provides a somewhat broader set of options in a user-friendly interface to create charts, reports, documents, and visualizations.
- App Studio. Includes a comprehensive and advanced set of tools and functionalities to create customized content and applications. Developers can create charts and reports enhanced with pre- and post-processing code, and add them to HTML pages.
Since you use these tools to create joins ad hoc for use in your content, they are saved as part of the individual procedure. They are not saved as part of the data source like joins in a cluster synonym are. Since joins made in your content are independent of the data source, this is a good way to perform quick data exploration.
When you select the synonyms that you want to join to for use in your content, they are joined automatically, if possible, based on whether the fields have a primary key-foreign key relationship or matching field names and formats. By default, the joins are shown in a flow view, which shows a simplified, linear representation of the joined data.
Each of these has a unique set of options that enables you to create and edit your joins. However, the basic concept of joining based on shared values remains the same. There are four types of joins that you can create, using either the WebFOCUS Reporting Server Console or WebFOCUS Designer. These different join types determine how the values in the parent (left) and child (right) tables are matched. Choose the type of join, based on the targeted result that you want to deliver.
- Inner join. Returns only records where the selected join fields match between the left-side table and the right-side table. If there are no matches, no records are returned. This is the default join type, since it ensures that values that are missing from either table are not returned.
- Left Outer. Returns all records from the left-side table, and only matched records from the right-side table.
- Right Outer. Returns all records from the right-side table, and only matched records from the left-side table.
- Full Outer. Returns all records, matched and unmatched, from the left-side table and the right-side table. This type of join can potentially return very large result-sets and can take longer to run.
Best Practice: There are many different ways to organize your data and configure your joins. When joining your data, it may be helpful to consider the following factors:
- Who is the end user of the data source? Is this a developer who is capable of joining the appropriate tables in a consistent manner themselves to create content in WebFOCUS Designer? If so, then you can create a series of synonyms that they can connect with joins themselves during their analysis or content creation in WebFOCUS Designer, allowing them to independently investigate a wide selection of related data sources.
Alternatively, the end-user may be a power user or business analyst, who just needs access to a synonym so they can create simple content and analytics on the fly, without having to configure their own joins. In this case, you may want to simplify what these users need to do themselves in WebFOCUS Designer by making all of the necessary joins in the metadata using a cluster synonym, which they can use as a data source to create their content. - Do you plan to reuse the same joins repeatedly in multiple content items? If the answer is yes, and you prefer to provide a consistent data source, then it may be best to join the tables at the metadata level, within your Business View. This ensures that the same exact join is repeated. This reduces the risk of errors or discrepancies produced by joining the tables in two different manners, such as an inner join in one instance and right-outer join in another instance, which can impact results, and produce different reporting outcomes. You can also use the Business View to limit the fields that are available when using the synonym to create content. This helps to improve performance and usability by limiting the availability of unnecessary or extraneous fields.
If the answer is no, and you prefer to give your users the flexibility of creating joins as they create their content, then you can create the synonyms and clusters that your users can then consume in WebFOCUS Designer. They can then opt to join tables ad-hoc or with any other data sources to which you provide access. - From what databases are you joining tables? Are the tables spread across multiple databases or are they in a single database location? Joining tables or files of different types and data sources will increase the processing time of the join request in WebFOCUS. Similarly, if it is necessary to use DEFINE fields to apply transformations to the data values in order to create your joins, there may be some impact on performance, depending on the complexity of the transformations.
- How familiar are you with the data sources that you are joining? When you select the tables or synonyms that you want to use as part of a cluster synonym or in a single content item, they are joined automatically, if possible, based on certain criteria. If the tables are stored in a relational data source, then they are joined automatically based on primary key and foreign key constraints. If the tables are not stored in a relational database, for example, if they are a flat file or spreadsheet, then they are joined automatically based on matching field names and field formats. Joins created automatically based on field names and formats may not be as accurate as those based on primary and foreign key relationships. This automatic join behavior means that you do not have to determine which tables and fields should be used to create each of your new joins, saving time if there are many tables that you are joining together or if you are uncertain of how to create your joins.
If you are familiar with the tables or synonyms for which you are creating your joins, you may wish to delete or edit some of the automatically created joins and create new joins based on your own specified criteria. When you create new joins, you can specify the existing segment to which the newly added table should be joined, the join type, and the fields from each table that should be used to create the join.
- Release: 8206
- Category: Connecting to Data, Data Management
- Product: Reporting Server, WebFOCUS Designer
- Tags: Best Practice